- 01.DATABASE
- 02.Tipologie di basi di dati
- 03.Perchè usare un DBMS
- 04.Processo di sviluppo di basi di dati
- 05.Linguaggi per l'accesso alle basi di dati
- 06.Progettazione di basi di dati relazionali
- 07.Raccolta e analisi dei requisiti
- 08.Progettazione concettuale
- 09.Esempio di schema concettuale
- 10.Progettazione logica
- 11.Progettazione fisica
- 12.Dallo schema concettuale allo schema logico
- 13.Normalizzazione
- 14.Prima forma normale
- 15.Seconda forma normale
- 16.Terza forma normale
" I DataBase (Base di Dati) "
01.DataBase
Undato(in inglese data) è un fatto noto che può essere memorizzato. UnaBase di Dati(database) è una collezioni di dati logicamente correlati. Essa modella una porzione della realtà. Deve essere consistente, cioè rappresentare fedelmente la realtà modellata. Ogni cambiamento nella realtà modellata deve riflettersi al più presto nella base di dati e ogni modifica della base di dati deve essere consistente con la realtà modellata. Una base di dati è costruita con uno scopo preciso, ha un determinato gruppo di utenti e un insieme di applicazioni a cui questi utenti sono interessati. Un sistema di gestione di basi di dati (DataBase Management System,DBMS) è uninsieme di programmiche permettono di: creare, popolare, manipolare e condividere una base di dati. I DBMS commerciali più popolari sono: Oracle Database, IBM DB2, e Microsoft SQL Server. I DBMS open source più famosi sono: PostgreSQL e MySQL.02.Tipologie di basi di dati
Le basi di dati più usate si fondano sulmodello dei dati relazionale. Esse modellano la realtà mediante un insieme di relazioni o tabelle. Una relazione possiede degli attributi dotati di un nome e un tipo. Le colonne contengono valori atomici del corrispondente tipo.03.Perchè usare un DBMS
Un DBMS permette di accedere in modo semplice e efficiente ad una base di dati mantenendone la consistenza, la privatezza e l'affidabilità. Il vantaggio dell'uso di un DBMS sono i seguenti: - Accesso ai dati tramite un linguaggio universale - Accesso efficiente ai dati. - Indipendenza dei dati - Controllo della ridondanza dei dati - Imposizione di vincoli di integrità sui dati - Atomicità delle operazioni - Accesso concorrente ai dati - Privatezza dei dati - Affidabilità dei dati Quando non usare un DBMS E' preferibile non usare un DBMS quando l'applicazione è semplice, relativamente stabile nel tempo e non prevede accesso concorrente da parte di più utenti. In tal caso meglio usare i file ordinari per archiviare i dati e delle procedure apposite per accedere ai dati. Un approccio intermedio tra i file ordinari e i DBMS consiste nell'uso di documenti XML. L'approccio basato su XML elimina gli svantaggi citati dell'uso dei DBMS in quanto un documento XML è semplicemente un file di testo che può essere archiviato sfruttando direttamente il file system. Inoltre, tale approccio offre strumenti oramai consolidati (e non proprietari) per definire gli schemi, interrogare, trasformare, e accedere ai dati tramite linguaggi di programmazione. Come detto questo approccio non offre i vantaggi di concorrenza, consistenza, privatezza e affidabilità dei dati tipici dei DBMS.04.Processo di sviluppo di basi di dati
La creazione di una base di dati è un processo che si sviluppa nelle seguenti fasi: - Raccolta e analisi dei requisiti - Progettazione concettuale della basi di dati - Scelta della tipologia della base di dati - Progettazione logica della base di dati - Scelta di un DBMS - Progettazione fisica della base di dati. - Realizzazione e ottimizzazione del sistema della base di dati. L'esecuzione di queste fasi è teoricamente sequenziale. E' importante notare che le fasi più importanti sono quelle più generali, cioè quelle iniziali. Infatti un errore in una fase iniziale, si ripercuote a cascata in tutte le fasi successive.05.Linguaggi per l'accesso alle basi di dati
I linguaggi per l'accesso alle basi di dati comprendono i seguenti linguaggi: - Linguaggio di definizione dei dati (data-definition language,DDL) Questo linguaggio permette di definire i tre livelli di astrazione della base di dati:esterno, logico e fisico. Linguaggio di manipolazione dei dati (data-manipulation language,DML) Questo linguaggio permette di: inserire, cancellare, modificare e reperire i dati. Illinguaggio SQLè un linguaggio dichiarativo globale che permette sia la definizione dei dati che la loro manipolazione in una base di dati relazionale. Una interrogazione (query) è una istruzione ben formata del linguaggio SQL.06.Progettazione di basi di dati relazionali
La progettazione si divide in progettazione dei dati e progettazione delle transazioni. Nella prima si individuano la struttura e l'organizzazione dei dati, nella seconda si definiscono le caratteristiche delle operazioni che usano i dati. Le due attività sono interconnesse e dovrebbero procedere in parallelo. Esiste una metodologia consolidata di progettazione di basi di dati che consiste nelle seguenti fasi: - raccolta e analisi dei requisiti: (fase 1) - progettazione concettuale: (fase 2) - progettazione logica: (fase 3) - progettazione fisica: (fase 4) Tale metodologia si fonda sul principio della separazione del cosa rappresentare in una base di dati (fasi 1 e 2) dal come farlo (fasi 3 e 4). Terminata la progettazione si passa alla realizzazione della base di dati che consiste: - nella creazione fisica delle strutture dei dati - nell'implementazione delle applicazioni che useranno la base di dati.07.Raccolta e analisi dei requisiti
La raccolta dei requisiti consiste nella individuazione delle caratteristiche statiche (dei dati) e dinamiche (delle operazioni) dell'applicazione da realizzare. I requisiti vengono raccolti in specifiche espresse in linguaggio naturale e per questo motivo spesso ambigue e disorganizzate. L'analisi dei requisiti consiste nel chiarimento e nell'organizzazione delle specifiche raccolte. Alcune regole generali per ottenere una specifica con meno ambiguità: - Evitare termini troppo generici o troppo precisi. Mantenere un livello di astrazione costante. - Evitare l'uso di sinonimi (termini diversi con il medesimo significato) e omonimi (termini uguali con differenti significati). Riferirsi allo stesso concetto sempre nello stesso modo. - Usare frasi brevi e semplici possibilmente uniformandone la struttura. - Dividere il testo in paragrafi. Dedicare ogni paragrafo alla descrizione di una specifica entità della realtà modellata. Evidenziare l'entità descritta in ogni paragrafo. E' fondamentale fin da questa fase differenziare le seguenti componenti del modello: 1.Entità. 2.Attributi delle entità. 3.Relazioni tra entità.08.PROGETTAZIONE CONCETTUALE
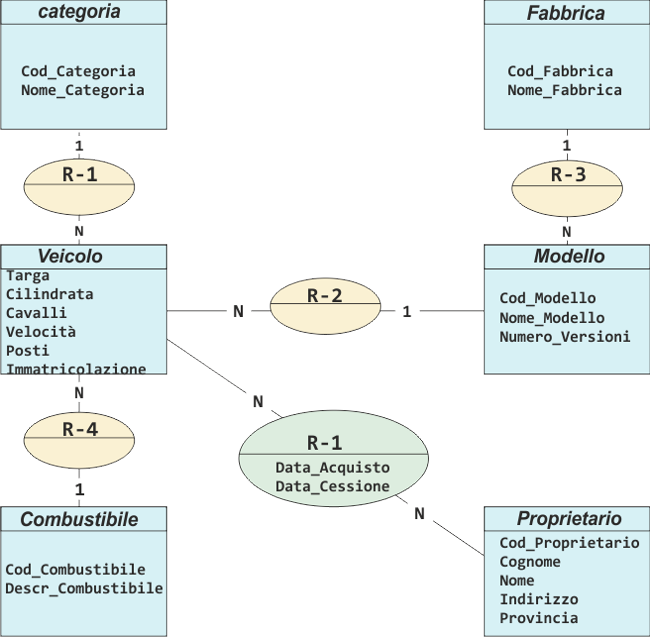
Lo schema concettuale, è la rappresentazione più astratta, ovvero più vicina alla logica umana, nella definizione di dati e relazioni. I modelli dei dati usati nella progettazione concettuale vengono definiti modelli semantici; il più diffuso è il modello (E-R, Entità-Relazione). Il modello Entità-Relazione prevede come prima attività l'individuazione di oggetti concreti o astratti; la loro classificazione in insiemi omogenei detti entità e viene rappresentato mediante un rettangolo. - Le proprietà caratteristiche di ciascuna entità vengono descritte mediante gli attributi. - Ciascun attributo è caratterizzato da un nome e da un dominio, - l'insieme dei valori che può assumere; Il modello prevede la rappresentazione di vincoli d'integrità i quali descrivono le regole che soddisfano gli oggetti della realtà.esempio di ENTITÀ:Veicolo Targa Cilindrata Combustibile Cavalli Fiscali Velocità Posti Immatricolazione Una relazione R tra due insiemi di entità E1 ed E2 viene classificata in base alla sua cardinalità. R ha cardinalità 1:1 (uno a uno) se a un elemento di E1 può corrispondere un solo elemento di E2 e viceversa. R ha cardinalità 1:N (uno a molti) se a ogni elemento di E1 possono corrispondere più elementi di E2 mentre a ogni elemento di E2 corrisponde al massimo un elemento di E1 R ha cardinalità N:N (molti a molti) se a ogni elemento di E1 possono corrispondere più elementi di E2 e viceversa.09.Esempio di Schema Concettuale
Nel seguente esempio viene illustrato lo schema concettuale del database di esempio Registro Automobilistico Il nostro database Registro Automobilistico, che fa ipoteticamente parte del sistema informativo di un ufficio di Motorizzazione, rappresenta la seguente situazione: - di ciascun veicolo interessa registrare la targa, la cilindrata, i cavalli fiscali, la velocità. il numero di posti, la data di immatricolazione; - i veicoli sono classificati in categorie (automobili, ciclomotori. camion, rimorchi ecc.); - ciascun veicolo appartiene a uno specifico modello; - tra i dati relativi ai veicoli vi è la codifica del tipo di combustibile utilizzato; - di ciascun modello di veicolo è registrata la fabbrica di produzione e il numero delle versioni prodotte; - ciascun veicolo può avere uno o più proprietari, che si succedono nel corso della durata del veicolo; di ciascun proprietario interessa registrare cognome, nome e indirizzo di residenza. Nel progetto concettuale vengono individuate le seguenti entità: ENTITÀ CATEGORIA Categoria Cod_Categoria Nome_Categoria Veicolo Targa Cilindrata Cavalli_Fiscali Velocità Posti Immatricolazione Modello Cod_Modello Nome_Modello Numero Versioni Fabbrica Cod_Fabbrica NomeFabbrica Proprietario Cod_Proprietario Cognome Nome Indirizzo Provincia Combustibile Cod_Combustibile DescrizioneCombustibile Tra tali insiemi di entità sussistono le seguenti relazioni:Schema concettuale Entità-Relazione del database Registro_automobilistico
- tra Categoria e Veicolo vi è una relazione di tipo 1:N, perché ciascuna categoria è comune a più veicoli, mentre un veicolo può appartenere a una sola categoria; - Modello e Veicolo sono in relazione 1:N, perché ciascun modello è comune a più veicoli e ciascun veicolo è di un solo modello; - Fabbrica e Modello sono in relazione 1:N perché una fabbrica può produrre più modelli, mentre un determinato modello viene prodotto da una sola fabbrica. - Combustibile e Veicolo sono in relazione 1:N, perché un tipo di combustibile è comune a più veicoli, mentre ciascun veicolo utilizza al più un tipo di combustibile; - Veicolo e Proprietario sono in relazione N:N, in quanto una persona può possedere più veicoli, e più persone possono succedersi nella proprietà di un veicolo nel corso del tempo; per rappresentare tale situazione la relazione ha come attributo la data di acquisto e la data di cessione del veicolo.
10.Progettazione Logica
La fase di progettazione logica del database ha lo scopo di tradurre lo schema concettuale in una rappresentazione mediante un modello logico dei dati. Un ulteriore compito della progettazione logica è di individuare all'interno dello schema logico del database le parti che sono rilevanti per le singole applicazioni; queste parti vengono definite viste o anche schemi esterni o sottoschemi.11.Progettazione Fisica
Nella progettazione fisica viene stabilito come le strutture definite a livello logico devono essere organizzate negli archivi e nelle strutture del file system. Essa dipende quindi non solo dal tipo di DBMS utilizzato, ma anche dal sistema operativo e in ultima istanza dalla piattaforma hardware del sistema che ospita il DBMS.12.Dallo Schema Concettuale allo Schema Logico
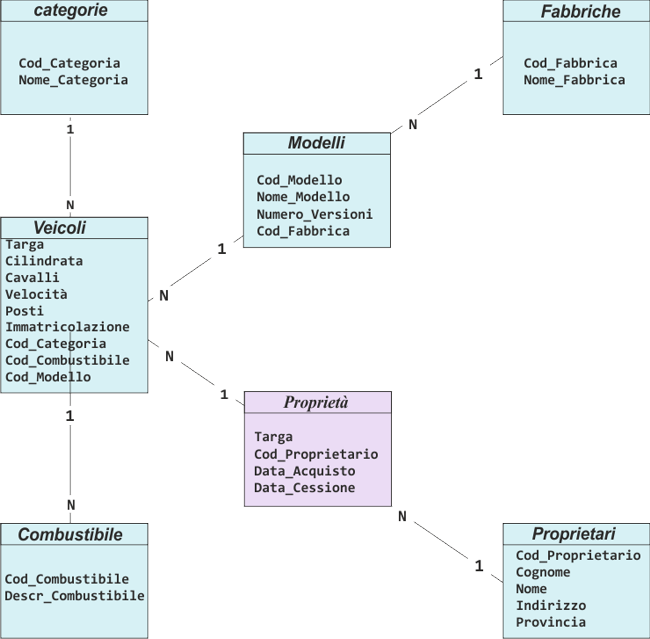
1. Per ciascuna entità dello schema concettuale viene definita una tabella nello schema logico: Veicoli, Categorie, Combustibili, Modelli, Fabbriche e Proprietari I nomi delle entità nello schema concettuale sono espressi al singolare (Veicolo, Categoria ecc.) nello schema logico, seguendo una convenzione spesso adottata, sono resi plurali (veicoli, Categorie ecc..) 2. Per ciascuna tabella viene definito un insieme di attributi con funzione di una chiave primaria che ne identifichi univocamente le righe. Se tale insieme non è individuabile tra gli attributi della tabella, verrà aggiunto un nuovo attributo finalizzato a questo scopo. Nel caso in cui gli attributi della chiave primaria facciano parte delle informazioni presenti nella tabella, la chiave primaria è detta naturale; nel caso in cui venga definito un attributo ad hoc, la chiave primaria e detta artificiale: Le tabelle corrispondenti agli insiemi di entità del database Registro_Automobilistico: Veicoli Modelli Targa: testo(10) Cod_Modello: testo(3) Cilindrata: numerico Nome_Modello: testo(30) Cavalli_Fiscali: numerico Numero_Versioni: numerico Velocità: numerico Posti: numerico Immatricolazione: data Categorie Fabbriche Cod_Categoria: testo(2) Cod_Fabbrica: testo(3) Nome_Categoria: testo(30) Nome_Fabbrica: testo(30) Proprietari Combustibili Cad_Proprietario: testo(5) Cod_Combustibile: testo(2) Cognome: testo(30) Descrizione_Combustibile: testo(30) Nome: testo(30) Indirizzo: testo(30) Provincia: testo(2) TABELLA CHIAVE PRIMARIAVeicoli Targa Categorie Cod_Categoria Combustibili Cod_Combustibile Modelli Cod_Modello Fabbriche Cod_Fabbrica Proprietari Cod_Proprietario1. Vengono definite le chiavi esterne per la rappresentazione delle relazioni 1:N tra Categorie e Veicoli, tra Combustibili e veicoli, tra Modelli e Veicoli e tra Fabbriche e Modelli. 2. Viene definita la nuova tabella Proprietà per la rappresentazione della relazione N:N tra Veicoli e Proprietari. Questa contiene, come chiave primaria, le chiavi primarie di Veicoli e Proprietari, e gli attributi Data Acquisto e Data Cessione, che costituiscono gli attributi della relazione. VEICOLI MODELLITarga Testo(10) Cod_Modello Testo(3) Cod Categoria Testo(2) Nome Modello Testo(30) Cilindrata numerico Cod_Fabbrica Testo(3) Cod Combustibile Testo(2) Numero versioni numerico Cavalli_Fiscali numerico Velocità numerico Posti numerico Immatricolazione data Cod_Modello Testo(3)Tabelle del database Registro_Automobilistico con le chiavi esterne per le relazioni 1 :N PROPRIETÀTarga: testo(10) Cod_Proprietario testo(5) Data_Acquisto data Data_Cessione dataTABELLA CHIAVE PRIMARIAProprietàTarga+Cod_ProprietarioRappresentazione delle relazioni N:N nel database Registro_AutomobilisticoRappresentazione dello schema logico relazionale di Registro_Automobilistico
13.Normalizzazione
Il termine normalizzazione indica il processo di organizzazione dei dati in un database. Tale processo comprende la creazione di tabelle e la definizione di relazioni tra di esse sulla base di regole progettate in modo da proteggere i dati e rendere il database più flessibile mediante l'eliminazione della ridondanza e delle dipendenze incoerenti. La presenza di dati ridondanti comporta uno spreco di spazio su disco nonché problemi di manutenzione. Se è necessario modificare dati presenti in più posizioni, la modifica deve essere effettuata ovunque seguendo le stesse modalità. Ad esempio, è più agevole implementare la modifica relativa all'indirizzo di un cliente se i dati relativi sono memorizzati solo nella tabella Clienti. Che cos'è una "dipendenza incoerente"? Mentre è intuitivo per un utente cercare nella tabella Clienti l'indirizzo di un cliente specifico, può non avere senso cercare in tale tabella le informazioni relative allo stipendio del dipendente che si occupa di quel cliente. Le informazioni sullo stipendio sono correlate al dipendente, ovvero sono dipendenti da quest'ultimo, pertanto devono essere spostate nella tabella Dipendenti. Le dipendenze incoerenti possono rendere difficile l'accesso ai dati, in quanto il percorso per la ricerca dei dati può risultare mancante o danneggiato. Per la normalizzazione dei database è necessario seguire alcune regole, ciascuna delle quali viene definita "forma normale". Se si osserva la prima regola, il database viene considerato nella "prima forma normale". Se si osservano le prime tre regole, il database viene considerato nella "terza forma normale". Sebbene siano possibili altri livelli di normalizzazione, la terza forma normale è considerata il livello massimo necessario per la maggior parte delle applicazioni.14.Prima Forma Normale
1 - Eliminare i gruppi ripetuti in singole tabelle.2 - Creare una tabella separata per ciascun insieme di dati correlati.3 - Identificare ciascun insieme di dati correlati associandovi una chiave primaria.Non utilizzare campi multipli in una singola tabella per memorizzare dati simili. Ad esempio, per controllare una voce di inventario proveniente da due possibili origini, è possibile creare un record di inventario contenente i campi per Codice fornitore 1 e Codice fornitore 2. Che cosa succede quando si aggiunge un terzo fornitore? La soluzione non consiste nell'aggiungere un campo. Sono infatti necessarie modifiche al programma e alla tabella che tuttavia non permettono di inserire agevolmente un numero dinamico di fornitori. È invece opportuno inserire tutte le informazioni sui fornitori in un'altra tabella denominata Fornitori e quindi collegare l'inventario ai fornitori tramite una chiave basata sul numero di voce oppure i fornitori all'inventario tramite una chiave basata sul codice fornitore.15.Seconda Forma Normale
4 - Creare tabelle separate per insiemi di valori validi per più record.5 - Correlare queste tabelle a una chiave esterna.I record devono dipendere solo dalla chiave primaria di una tabella, se necessario una chiave composta. Si consideri, ad esempio, l'indirizzo di un cliente in un sistema contabile. Si noterà che l'indirizzo è richiesto non solo dalla tabella Clienti, ma anche dalle tabelle Ordini, Spedizioni, Fatture, Contabilità fornitori e Raccolte. Invece di memorizzare l'indirizzo del cliente come voce separata in ciascuna tabella, è preferibile memorizzarlo in un'unica tabella, ovvero nella tabella Clienti oppure in una tabella Indirizzi separata.16.Terza Forma Normale
6 - Eliminare i campi che non dipendono dalla chiave.I valori di un record non compresi nella relativa chiave non appartengono alla tabella. In generale, ogni volta che il contenuto di un gruppo di campi può essere applicabile a più record della tabella, provare a inserire tali campi in una tabella separata. Ad esempio, in una tabella Colloqui di assunzione è possibile includere il nome e l'indirizzo dell'università dei candidati. Per i gruppi di distribuzione è tuttavia necessario disporre di un elenco completo di università. Se le informazioni sull'università sono memorizzate nella tabella Candidati, non sarà possibile ottenere l'elenco delle università non associate ai candidati correnti. Creare una tabella Università separata e collegarla alla tabella Candidati utilizzando una chiave basata sul codice università. ECCEZIONE: l'adozione della terza forma normale non è sempre pratica anche se teoricamente auspicabile. Se si dispone di una tabella Clienti e si desidera eliminare tutte le possibili dipendenze tra campi, è necessario creare tabelle separate per città, CAP, rappresentanti, classi di clienti e gli eventuali altri fattori che possono essere duplicati in più record. Nella teoria la normalizzazione è sempre auspicabile, tuttavia l'utilizzo di un numero elevato di tabelle di dimensioni limitate può determinare una riduzione del livello delle prestazioni oppure richiedere capacità di memoria e di apertura dei file superiori a quelle disponibili. Può risultare più appropriato applicare la terza forma normale solo ai dati soggetti a frequenti modifiche. Se sussistono dei campi dipendenti, progettare l'applicazione in modo da richiedere la verifica di tutti i campi correlati in caso di modifica di un campo.